Unveiling the Potential of Multimodal Large Language Models for Scene Text Segmentation via Semantic-Enhanced Features
김형규 Immersive Reality & Intelligent Systems Lab
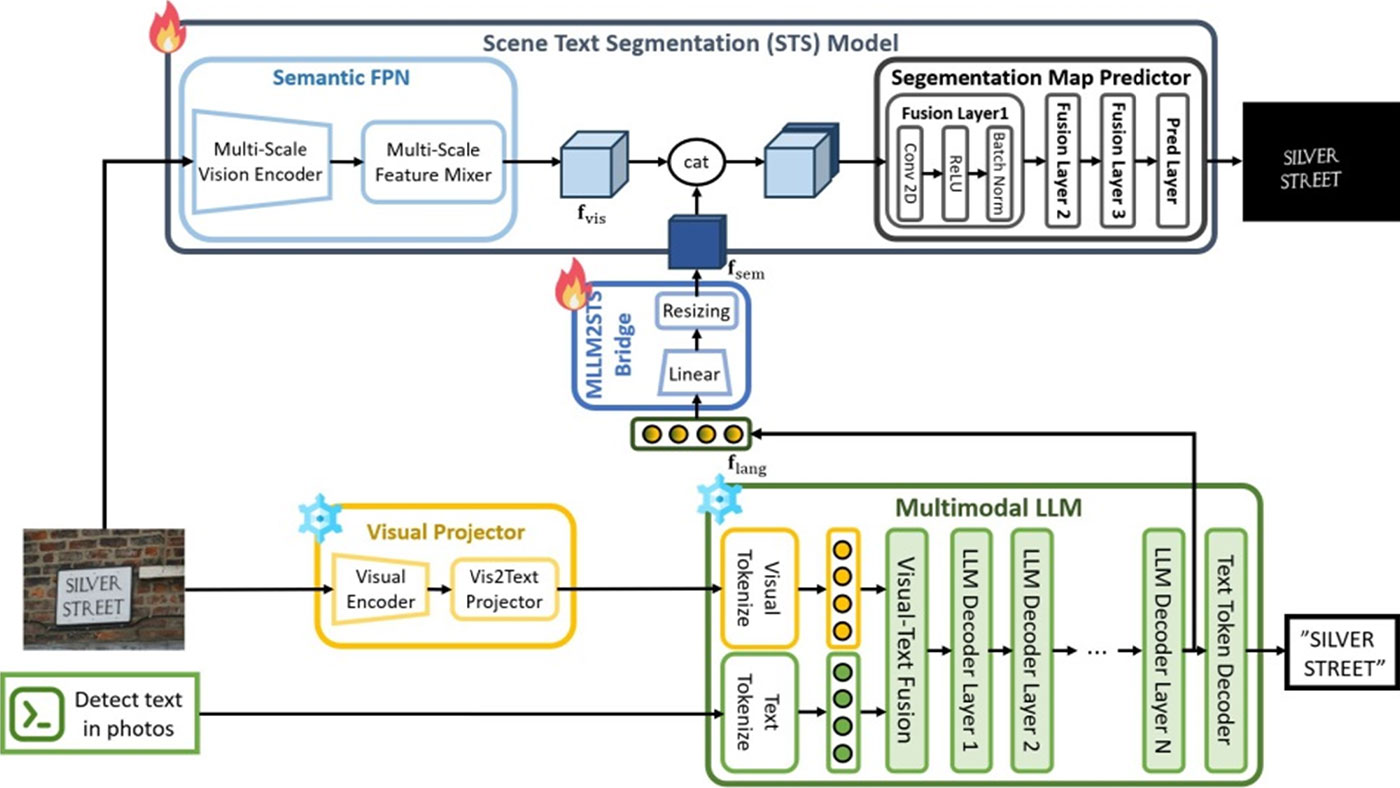
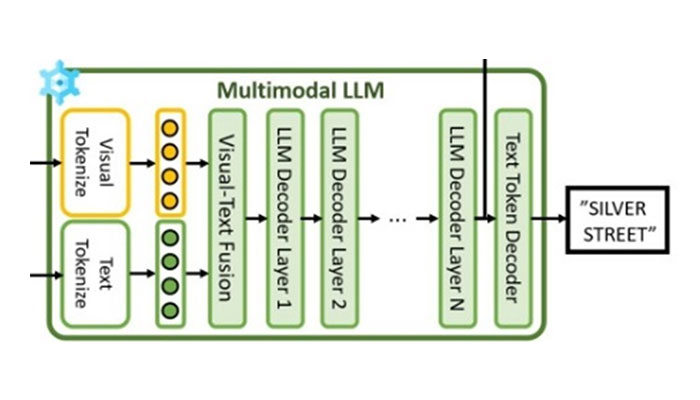
본 연구는 장면 텍스트 분할은 배경 이미지나 그래픽 요소와 같은 비텍스트적 요소를 무시하면서 장면 내의 텍스트 영역을 정확하게 식별하는 것입니다. 그러나 현 재의 텍스트 분할 모델은 복잡한 배경 노이즈나 다양한 글꼴 스타일 및 크기로 인해 텍스트 영역을 정확하게 분할하지 못하는 경우가 많습니다. 이 문제를 해결하려 면 장면 텍스트 분할에서 시각적 정보뿐만 아니라 텍스트의 의미 정보도 고려하는 것이 필수적입니다. 이를 위해 다중 모달 대규모 언어 모델(MLLM)을 통합하여 시각적, 텍스트 및 언어적 정보를 융합하는 새로운 의 미 인식 장면 텍스트 분할 프레임워크를 제안합니다. 다중 모달 LLM의 의미 강화 기능을 활용함으로써 장 면 텍스트 분할 모델은 시각적으로 혼란스럽지만 텍스 트로 인식되지 않는 거짓 양성을 제거할 수 있습니다. 정성적 및 정량적 평가 모두 다중 모달 LLM이 장면 텍스트 분할 성능을 개선한다는 것을 보여줍니다.