-

- ARCHIVE
MV CIMF Festival

Subjective Evaluation on Generative Models for Mosaic Media Art
계다현 Creative Vision and Multimedia Lab
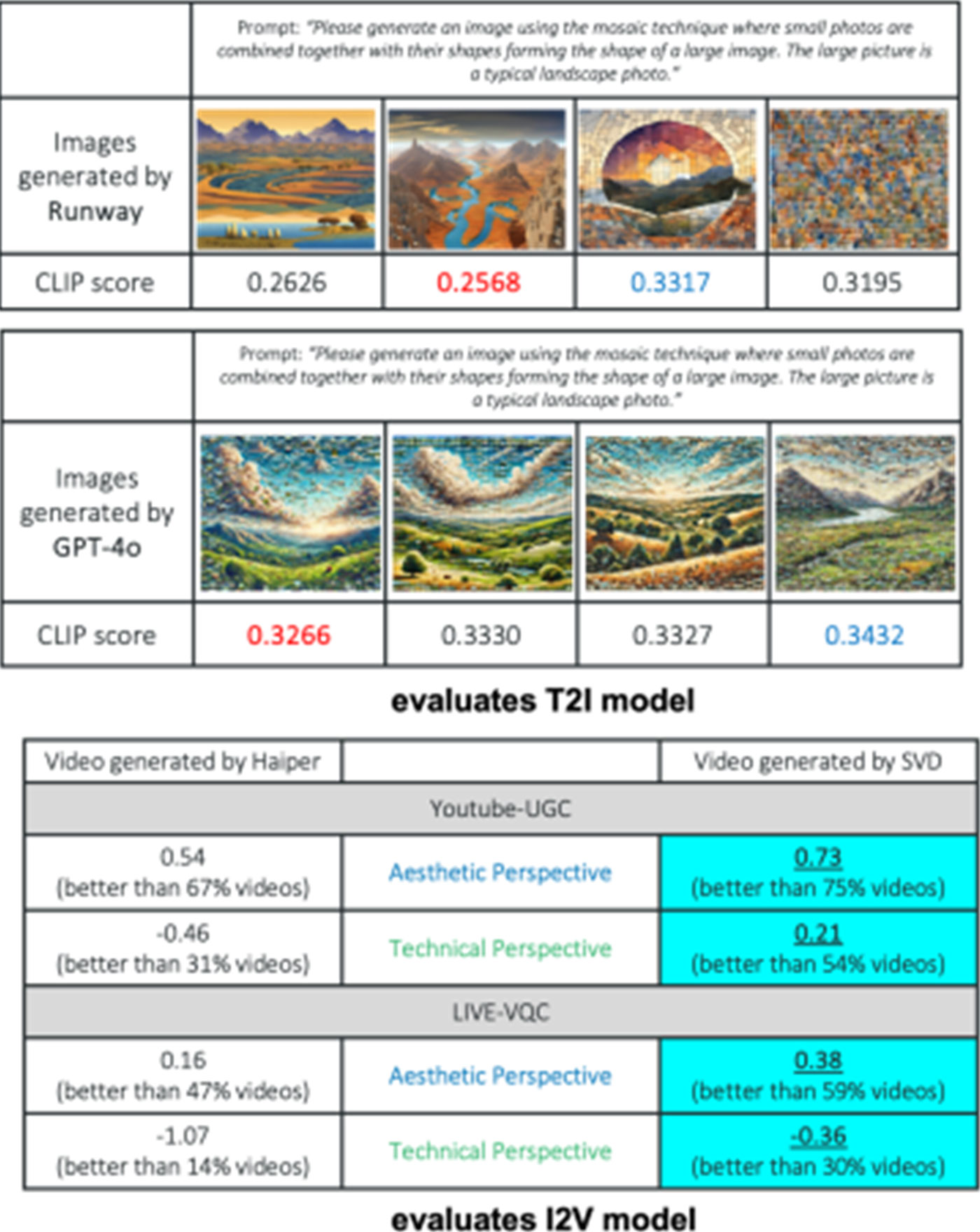
본 연구는 모자이크 미디어 아트 비디오를 제작하기 위해 다양한 생성 모델을 평가하는 것을 목표로 합니다. 특히, 텍스트를 이미지로 변환하는 과정에서는 Runway와 ChatGPT-4o를 활용하고, Stable Video Diffusion (SVD)와 HaiPer를 사용하여 이미지를 비디오로 변환하는 과정을 진행합니다. 각기 다른 텍스트 프롬프트를 사용하여 이미지를 생성한 뒤 이를 비디오 시퀀스로 변환하며, 시각적 완성도, 시간적 일관성, 조작 정확성 등의 기준으로 평가를 진행합니다.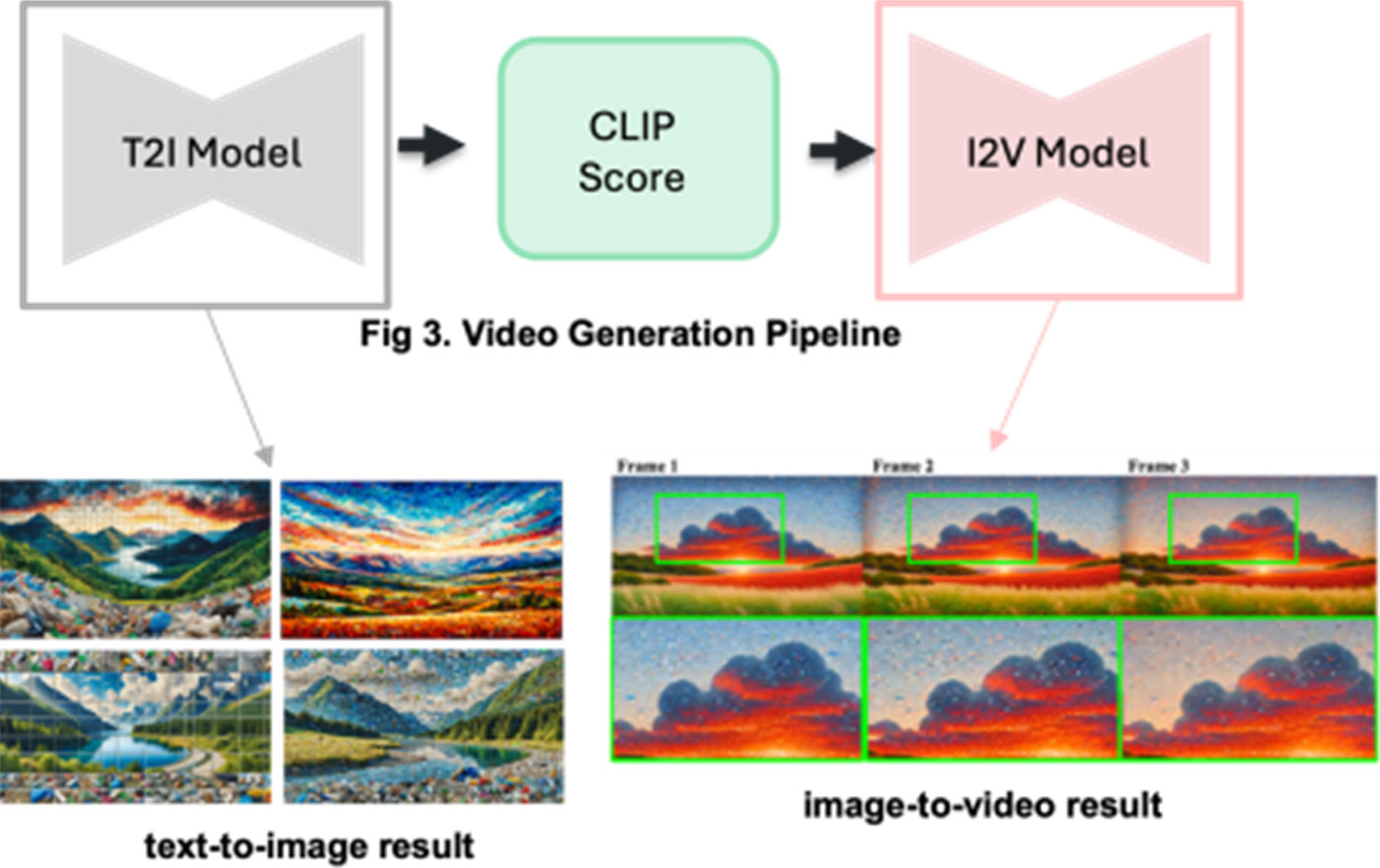
중앙대학교 메타버스융합대학원



06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.